Containing Indirect Prompt Injection in Tool-Using Agents
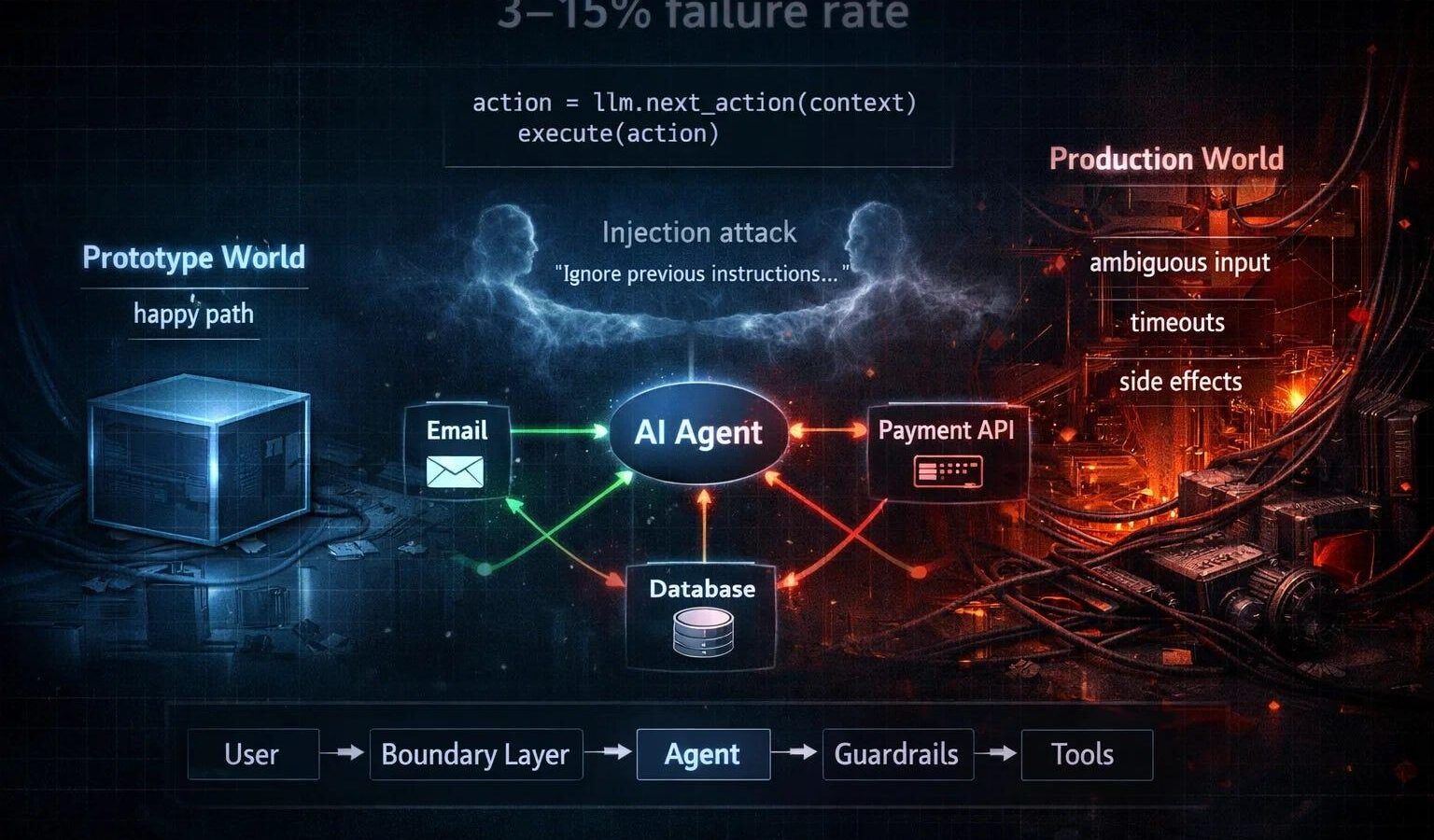
By 2026 the threat model for tool-using LLM agents is settled enough that we can stop arguing about whether indirect prompt injection (IPI) is a real risk and start arguing about which mitigations are load-bearing. The honest answer is that none of them are sufficient on their own, and the deployments that survive contact with adversarial content do so because they treat the agent runtime the way we treat a browser: an untrusted execution environment that gets sandboxed, monitored, and stripped of authority by default.
The failure pattern is consistent. An agent with retrieval, browsing, or email-reading tools ingests attacker-controlled text. That text contains instructions — sometimes overt, often steganographic, occasionally encoded in markup or zero-width Unicode — that redirect the agent toward exfiltration, privilege escalation across connectors, or silent data corruption. The model doesn’t “fall for” anything in a human sense. It is doing exactly what it was trained to do: follow instructions in its context window. The defect is architectural.
The control surface, not the model
Vendors keep promising injection-resistant models. Treat those claims as you would treat a sandbox escape mitigation in a browser: helpful, never sufficient. The 2024–2025 evaluation work (AgentDojo, InjecAgent, the Anthropic and DeepMind red-team disclosures) made it clear that even instruction-hierarchy training reduces success rates rather than eliminating them, and adversaries adapt within days. Plan for residual probability of compromise on every tool call and design the surrounding controls to make that compromise survivable.
The useful frame is the CaMeL-style separation popularized in 2024 and now showing up in production frameworks: a privileged planner that never sees untrusted content, and an unprivileged executor that sees the content but cannot issue tool calls outside a pre-authorized plan. This maps cleanly to AC-3 (access enforcement) and AC-6 (least privilege) at the agent-action layer rather than the user-identity layer. Most ATO packages still describe agents as if they were applications acting on behalf of a single user. They are not. Each tool invocation is its own authorization decision and should be modeled that way.
What is actually working
Four patterns are doing the heavy lifting in deployments I have reviewed this year.
Plan-then-execute with frozen capability tokens. The planner produces a structured plan before any untrusted content enters context. The executor receives capability tokens scoped to the specific resources named in the plan — a particular document ID, a specific recipient address, a single SQL view. Anything the executor tries that wasn’t in the plan is rejected at the broker, not negotiated with the model. This kills the entire class of attacks that rely on convincing the agent to email a different recipient or query a different table.
Provenance-tagged context. Every span in the context window carries a label — trusted_user, system, tool_output:web, tool_output:email_body — and the policy engine consults those labels when the model proposes an action. A plan derived from tool_output:web cannot authorize sends to external recipients; a summary derived from email_body cannot trigger calendar writes. This is essentially taint tracking, and it works because the failure modes are loud rather than silent. Maps to SI-10 (input validation) and AU-2 (auditable events) when the labels are logged with each decision.
Egress chokepoints. The single highest-leverage control remains an outbound proxy that enforces an allowlist of destinations per agent role, with DLP inspection on payloads. Most successful IPI exfiltrations in the public incident corpus go to attacker-controlled HTTPS endpoints or use markdown image rendering to leak via referer-style URLs. Block image fetches from agent-rendered markdown, strip outbound URLs to an allowlist, and the exfil channel collapses. SC-7 boundary protection earns its keep here.
Human-in-the-loop on irreversible actions. Define irreversibility narrowly and enforce it strictly: external sends, payments, deletes, ACL changes, anything touching shared state. Confirmation prompts must surface the resolved parameters — actual recipient, actual file path, actual amount — not the model’s natural-language summary, because the summary is exactly what an injection will lie about. This is AC-3(2) dual authorization in spirit, even when the second principal is the same user.
Control mapping
| Defense | Primary 800-53 controls | What it actually buys you |
|---|---|---|
| Plan/execute separation | AC-3, AC-6, CM-7 | Bounds the action space before adversarial content arrives |
| Provenance tagging | SI-10, AU-2, AU-12 | Makes label-violating actions detectable and blockable |
| Egress allowlisting | SC-7, SC-7(5), SI-4 | Removes the dominant exfiltration channel |
| Resolved-parameter confirmation | AC-3, AC-14 | Defeats summary-spoofing in HITL flows |
| Tool output sanitization | SI-10, SI-15 | Reduces in-band instruction surface, not eliminate it |
| Per-tool rate and scope limits | AC-6(9), SC-5 | Caps blast radius of a successful injection |
Where the gaps still are
Multi-agent systems remain underdefended. When agent A’s output becomes agent B’s input, the provenance label needs to travel with it, and almost no orchestration framework does this correctly across process boundaries. The result is privilege laundering: a low-trust scrape gets summarized by a mid-trust agent, and the summary is treated as system-grade by a downstream planner. If you operate a multi-agent stack, audit the label propagation across the entire dataflow before you audit anything else.
Memory is the second gap. Long-term agent memory stores ingest the same untrusted content as the live context, with the added problem that a successful injection persists across sessions. Treat memory writes as an authorization-relevant action, sign and timestamp them (AU-10 non-repudiation is not a stretch here), and require provenance review before any memory-derived content is admitted to a planner role.
The third gap is evaluation. Static red-team suites age out within a quarter. The deployments that hold up run continuous adversarial evaluation against their actual tool topology, not a generic benchmark, and they treat regressions in injection resistance as release blockers. CA-7 continuous monitoring should explicitly include agent-behavior drift, not only infrastructure posture.
IPI is not going to be solved at the model layer in 2026, and probably not in 2027. Build the runtime as if the model will be compromised on every call, log enough to prove what happened when it is, and keep the irreversible actions behind a wall the model cannot talk its way through.