Control-Flow Integrity for LLM Agents: Beyond Prompt Injection Whack-a-Mole
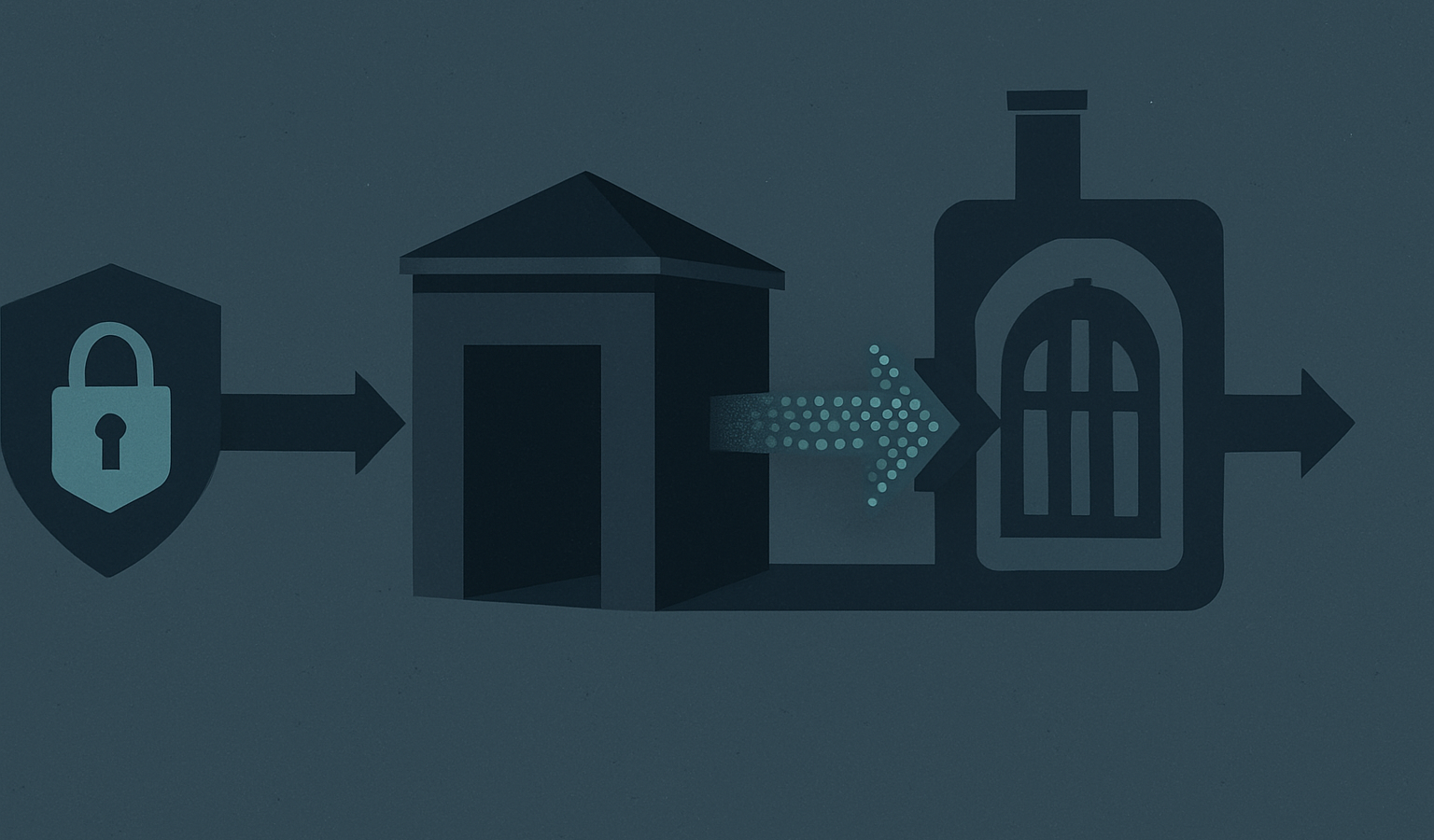
By 2026 the agentic AI conversation has finally moved past chatbot demos. Production deployments at scale — coding agents with repo write access, SOC triage agents talking to SIEM and EDR APIs, procurement agents hitting ERP systems — have made one thing painfully clear: every input-side guardrail eventually fails, and the consequences are no longer a snarky reply but a destructive tool call. The architecture pattern that’s actually starting to hold up under red team pressure isn’t a smarter classifier in front of the LLM. It’s treating the agent loop like a system with a control plane and a data plane, and refusing to let untrusted tokens cross between them.
This post is about that pattern, why ad-hoc prompt-injection defenses keep losing, and how the design maps onto familiar 800-53 control families when you have to write it up for an authorizing official.
Why input filtering keeps losing
The core failure mode hasn’t changed since Greshake’s indirect prompt injection paper: an LLM cannot reliably distinguish instructions from data when both arrive as tokens in the same context window. Every patch — system prompt hardening, spotlighting, instruction hierarchies, classifier-based input filters, output filters, even constitutional-style self-check passes — is a probabilistic mitigation against an adversary with unbounded creativity in the input space. Attackers in 2025 demonstrated reliable bypass against every commercial guardrail product within weeks of release, including via Unicode tag smuggling, multimodal payloads embedded in image alt-text rendered to the model, and tool-output exfiltration through markdown image rendering.
The lesson: any defense that depends on the model recognizing malicious intent in its context is, at best, defense in depth. It cannot be the load-bearing control. If your agent has authority to call delete_repository or send_payment, your authorization story cannot bottom out at “the model is supposed to know better.”
The control-plane / data-plane split
The architectural fix that’s gaining traction — variations of CaMeL from DeepMind, the dual-LLM pattern Simon Willison sketched in 2023, and several capability-based agent frameworks shipping in 2026 — share one structural property. A privileged planner model sees only trusted instructions: the user goal and the system policy. It emits a typed plan, often as a constrained DSL or a graph of tool calls with symbolic placeholders for values it has not yet seen. A separate quarantined model, with no tool access whatsoever, processes untrusted content (web pages, emails, ticket bodies, retrieved documents) and produces structured extractions that bind to those placeholders.
The planner never sees raw untrusted tokens. The executor never sees free-form instructions. Tool invocations are dispatched by a deterministic interpreter that enforces capability constraints attached to each value: a string scraped from an email carries a taint label that forbids it from being passed as the recipient of send_email or as a path to fs.write. Policy violations are caught at the interpreter, not by asking a model nicely.
This is, structurally, the same idea as W^X memory or CFI in binaries. You don’t try to detect malicious instructions in the data section. You make data non-executable.
What this looks like in practice
A coding agent built this way might decompose into:
planner_llm(goal, policy) -> Plan
Plan := Step+
Step := tool_call(name, args) where args reference TaintedValue ids
executor(plan):
for step in plan:
check_capabilities(step, taint_labels)
result = dispatch(step)
if result.untrusted:
result = quarantine_llm.extract(result, schema)
result.taint = UNTRUSTED
The non-obvious work is the policy language. “Untrusted strings cannot become shell arguments” is easy. “A file path read from a code review comment cannot be written to outside the repo’s working tree” requires a real type system over capabilities, with provenance tracking through transformations. Several 2026 frameworks (Anthropic’s tool-use schema extensions, the open-source agentkit-cap project, Microsoft’s Inner Loop work) are converging on labels-plus-policy rather than free-form sandboxing.
Mapping to 800-53
When you write the SSP, this architecture has the pleasant property of mapping cleanly to existing control families rather than requiring hand-waving overlays.
| Control | How the pattern satisfies it |
|---|---|
| AC-3, AC-4 | Capability labels enforce mediated access and information flow between trust domains |
| AC-6 | Planner runs with the user’s authority; quarantine model runs with none |
| SC-3 | Hard separation of planner, executor, and quarantine model processes |
| SC-7 | Tool dispatcher is the only egress; no model directly invokes external services |
| SI-10 | Structured-output extraction validates all untrusted content against a schema |
| SI-7 | Plan integrity: signed plans, deterministic execution, no mid-flight replanning on untrusted content |
| AU-2, AU-12 | Every tool invocation is interpreter-mediated, so logging is complete and tamper-evident |
| CA-7 | Policy violations surface as interpreter exceptions, not buried model behavior |
The AU story alone is worth the architectural cost. Auditing a freeform ReAct loop is nearly impossible — the model can decide to stop logging, lie about what it did, or chain tool calls the logger didn’t anticipate. An interpreter-mediated agent produces an audit trail with the same fidelity as a syscall log.
Where it breaks
Honest caveats. Capability systems are only as good as the policy you write, and writing policy for general-purpose agents is hard. The quarantine model still has to be correct enough to extract structured fields without being tricked into lying about them — though lying in a typed schema is a much narrower attack surface than free-form output. Latency goes up: two model calls plus a structured extraction per untrusted input. And expressiveness drops, which is the real reason vendors resist this design — a fully constrained agent is less impressive in demos than one that improvises.
There are also hard cases the pattern doesn’t solve. Side-channel exfiltration through plan-shape choices. Adversarial inputs that corrupt the quarantine model’s extraction in semantically valid ways. Multi-tenant memory poisoning where an attacker plants content today that the planner trusts tomorrow. RA-3 and SR-3 still apply.
The takeaway for ATO work
If you’re an ISSO looking at an agentic system and the answer to “how do you prevent prompt injection from causing unauthorized tool execution” is a list of mitigations on the input side, that system is not authorizable for anything that touches consequential actions. Ask for the control-flow architecture. Ask where the trust boundary is between instruction tokens and data tokens. If the team can’t draw it on a whiteboard, there isn’t one.
The agents that survive the next two years of red teaming will be the ones designed like operating systems, not like chatbots with extra steps.