Pod Security and Container Escape Surface in Shared Kubernetes Clusters
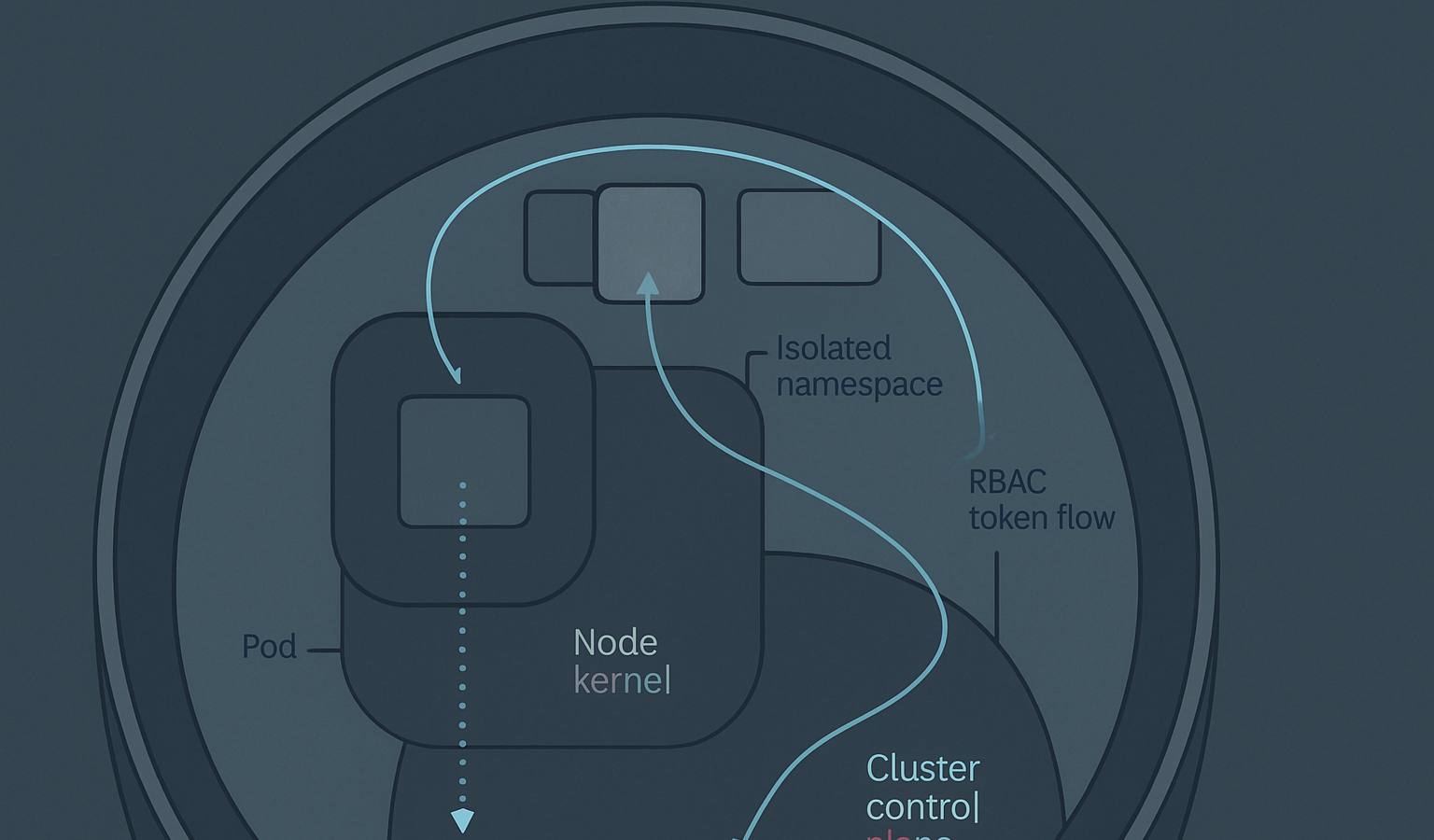
Multi-tenant Kubernetes is the cheapest way to lose isolation you thought you had. The control plane gives every namespace the appearance of separation, but the kernel underneath is a single shared object, and the abstractions that platform teams rely on — namespaces, cgroups, seccomp, LSMs — are defense in depth around that one fact. Once you accept that, the question stops being can a container escape? and becomes how much work is it, and what do you have in the way? On a shared cluster carrying workloads from teams with different threat models, that question is operational, not theoretical.
What “escape” actually means here
Container escape is a loose term covering at least four distinct outcomes, and conflating them muddles the threat model.
- Namespace-level escape inside the same pod or node — breaking out of the container into the host PID, mount, or network namespace, typically via a misconfigured
securityContextor a privileged sidecar. - Node compromise from a workload — full root on the kubelet host, usually through a kernel vulnerability, a writable host mount, or abuse of
hostPath,hostNetwork,hostPID. - Cross-tenant lateral movement — leveraging a node compromise (or a stolen kubelet credential, or a service account with cluster-wide read) to reach another tenant’s workloads or secrets.
- Control-plane compromise — pivoting from a node or a pod with an over-scoped service account to the API server, etcd, or a cluster-admin-bound controller.
The interesting failures in production almost always chain 1→2→3. The control-plane case is rarer but catastrophic, and it is usually a CM/AC failure (a bound role nobody audited) rather than a kernel bug.
The realistic escape surface
Privileged and near-privileged pods. privileged: true is the obvious one and Pod Security Admission’s restricted profile rejects it. The subtler problems are pods that aren’t privileged but might as well be: CAP_SYS_ADMIN, CAP_NET_ADMIN, CAP_SYS_PTRACE, hostPID, hostNetwork, hostPath mounts of /, /var/run/docker.sock, /var/lib/kubelet, or /proc. Each of these collapses a specific isolation boundary. A hostPath mount of the containerd or CRI-O socket is functionally equivalent to root on the node.
The kernel itself. Container runtimes share the host kernel, so any local privilege escalation CVE in the kernel is, by default, a container escape. Dirty Pipe (CVE-2022-0847), the cgroups v1 release_agent issue (CVE-2022-0492), nf_tables UAFs, io_uring bugs — these all landed as container escapes because seccomp profiles in real clusters rarely block enough syscalls to matter. The default Docker seccomp profile is reasonable; the default Kubernetes pod seccomp profile is unconfined unless you explicitly set seccompProfile: RuntimeDefault. That single field is one of the highest-leverage hardening changes available.
Runtime and image-handling bugs. runc CVE-2019-5736 (overwriting the runc binary from inside a container), CVE-2024-21626 (the leaked file descriptor / WORKDIR issue), and the various containerd image-pull path traversals are the canonical examples. They are infrequent but they hit every cluster on a vulnerable version simultaneously. Patch latency on worker nodes is the metric that matters here, and it is almost always worse than the platform team claims.
Service account token abuse. Every pod gets a projected service account token by default. If the bound role can get secrets cluster-wide, or create pods in kube-system, or escalate on roles, a single compromised workload becomes a cluster takeover without any kernel work at all. This is not a container escape in the kernel sense, but it is the same outcome and it is dramatically more common.
Shared node resources. Co-tenant side channels — /sys, /proc, cgroup stats, kernel keyrings, eBPF programs loaded by privileged DaemonSets — leak more than people expect. eBPF in particular is a double-edged tool: excellent for observability, terrible if a tenant can load programs.
Controls that actually move the needle
Most hardening guides read like a checklist of every Kubernetes flag ever shipped. The short list that disproportionately reduces escape surface:
| Control | Mechanism | 800-53 mapping |
|---|---|---|
Pod Security Admission restricted enforced cluster-wide |
Blocks privileged, hostPath, hostNetwork, capability adds | AC-3, AC-6, CM-7 |
seccompProfile: RuntimeDefault as a default |
Cuts kernel syscall surface materially | SC-39, SI-3 |
| AppArmor or SELinux in enforcing mode on nodes | LSM mediation independent of namespaces | SC-39, SI-7 |
Per-namespace, narrowly scoped service accounts; automountServiceAccountToken: false by default |
Kills the easy SA-token pivot | AC-2, AC-6, IA-5 |
| Image provenance and admission (cosign + policy controller) | Stops unsigned or unknown images | SR-3, SR-4, CM-5, SI-7 |
| Network policies default-deny, egress included | Limits blast radius of node or pod compromise | SC-7, AC-4 |
| Node auto-patching with bounded SLA on kernel and runtime CVEs | Closes the LPE-as-escape window | SI-2, RA-5, MA-2 |
Audit logging on the API server with retention and alerting on exec, attach, impersonate, RBAC changes |
Detects abuse paths | AU-2, AU-6, AU-12, IR-4 |
| Workload-level isolation for hostile-tenant cases: gVisor, Kata, or dedicated node pools | Separate kernel or VM boundary | SC-3, SC-7(21), SC-39 |
The last row is the one platform teams resist and the one that matters most when tenants don’t trust each other. PSA, seccomp, and AppArmor are kernel-shared defenses. If your threat model includes a malicious tenant — not a sloppy one, an actively malicious one — kernel sharing is the wrong abstraction. gVisor adds a user-space kernel; Kata adds a lightweight VM. Both have real performance tradeoffs and both are cheaper than an incident.
Where assessments tend to go wrong
Assessors on shared clusters spend too much time on the API server’s TLS posture and not enough on RBAC graphs. The questions worth asking on an authorization package or continuous monitoring review:
- Which ServiceAccounts can
create podsorpatch podsin any namespace that hosts a privileged DaemonSet? Those SAs are effectively node-root. - Which roles include
*verbs or*resources? Every wildcard is a finding. - What is the actual seccomp profile on running pods, not the cluster default? Validate with
crictl inspect, not the manifest. - What is the patch SLA on the node OS and on the container runtime, separately? They diverge.
- Are admission policies failing closed? An OPA/Kyverno controller in
warnmode is documentation, not control. - Does audit logging actually capture
execinto pods, and does anyone look at it (AU-6)?
If the answers are vague, the cluster is one CVE or one bound role away from a bad week.
The honest summary
Shared Kubernetes clusters are workable for cooperating tenants with similar trust levels and disciplined platform engineering. They are a poor fit for hostile multi-tenancy unless you accept the cost of sandboxed runtimes or VM-isolated pods. Pod Security Admission, RuntimeDefault seccomp, narrow RBAC, signed images, and aggressive node patching are not optional — they are the floor. Everything above that floor is a function of how much you trust the workloads sharing your kernel.